
رشتهها یا بصورت خلاصه str در پایتون یکی از data typeهای پایهای هستند که برای نمایش متن به کار میروند. یک رشته توالیای از کاراکترهاست که درون کوتیشن (تک ‘ یا دوبل “”) قرار میگیرد. در این درس با نحوهی کار با رشته یا استرینگ در پایتون بصورت کامل آشنا میشویم. مباحثی که پوشش خواهیم داد عبارتند از برش رشتهها(slicing)، ویرایش و تغییر رشتهها, چسباندن رشتهها به یکدیگر(concat )، فرمتدهی به رشتهها، استفاده از کاراکترهای ویژه، و متدهای رایج رشتهای. هر بخش با مثالهای عملی همراه است تا هم مبتدیان و هم برنامهنویسان حرفهای بتوانند نکات مفیدی بیاموزند.
برش رشتهها (Slicing Strings)
یکی از امکانات قدرتمند رشتهها در پایتون برش (slicing) است که به شما اجازه میدهد یک زیررشته (substring) از رشتهی اصلی استخراج کنید. برای برش یک رشته از سینتکس string[start: end] استفاده میشود؛ به این صورت که ایندکس شروع start و ایندکس پایان end را با علامت دونقطه از هم جدا میکنیم. ایندکسها از صفر شمارهگذاری میشوند (یعنی اولین کاراکتر رشته ایندکس 0 دارد) و زیررشته شامل کاراکترهای بین ایندکس شروع تا یک کاراکتر قبل از ایندکس پایان خواهد بود
به عبارت دیگر، کاراکتری که در موقعیت end قرار دارد در زیررشته لحاظ نمیشود.
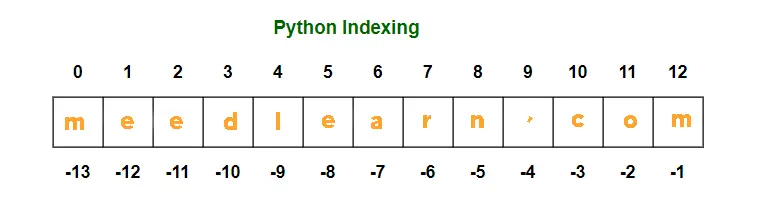 نمایش مفهوم ایندکسگذاری یک رشته (مثال: رشته “meedlearn.com” که ایندکسهای 0 تا 12 از ابتدا و -13 تا -1 از انتها را نشان میدهد) اگر ایندکس شروع را ننویسیم، برش از ابتدای رشته آغاز میشود و اگر ایندکس پایان خالی بماند، برش تا انتهای رشته ادامه پیدا میکند. به عنوان مثال:
نمایش مفهوم ایندکسگذاری یک رشته (مثال: رشته “meedlearn.com” که ایندکسهای 0 تا 12 از ابتدا و -13 تا -1 از انتها را نشان میدهد) اگر ایندکس شروع را ننویسیم، برش از ابتدای رشته آغاز میشود و اگر ایندکس پایان خالی بماند، برش تا انتهای رشته ادامه پیدا میکند. به عنوان مثال:
text = "Hello, World!"
print(text[:5]) # خروجی: Hello
print(text[7:]) # خروجی: World!
در مثال بالا text[:5] کاراکترهای ابتدا تا قبل از ایندکس 5 (یعنی “Hello”) و text[7:] کاراکترهای از ایندکس 7 تا انتها (یعنی “!World”) را چاپ می کند. همچنین میتوانید از ایندکسهای منفی برای برش از انتهای رشته استفاده کنید. برای نمونه، عبارت text[-6:-1] زیررشتهای از شش کاراکتر انتهایی رشته (به جز آخرین کاراکتر) را برمیگرداند:
print(text[-6:-1]) # خروجی: World
در اینجا از ایندکس منفی 6- (ششمین کاراکتر از انتها) تا ایندکس 1- (آخرین کاراکتر، که خودش شامل نمیشود) برش انجام شده است و کلمهی “World” حاصل شده است. علاوه بر این میتوان گام (step) برش را نیز مشخص کرد. سینتکس کامل برش به صورت string[start: end: step] است
به طور پیشفرض step برابر 1 است که به معنی انتخاب پیوستهی کاراکترهاست. اگر step را 2 قرار دهیم، کاراکترها را دو تا یکی برمیدارد. مثلا:
text = "abcdefg"
print(text[0:7:2]) # خروجی: aceg
در این مثال از ایندکس 0 تا 6 با گام 2 برش زدیم و هر دو کاراکتر یکی را انتخاب کردیم. جالبتر اینکه اگر مقدار step منفی باشد میتوان برش را در جهت معکوس انجام داد. برای مثال text[::-1] رشته را معکوس میکند:
print(text[::-1]) # خروجی: gfedcba
این ترفند ساده برای برعکس کردن رشتهها مفید است و حتی بسیاری از برنامهنویسان حرفهای ممکن است آن را به کار ببرند.
ویرایش رشتهها (Modify Strings)
در پایتون رشتهها غیرقابل تغییر (immutable) هستند، به این معنی که پس از ایجاد یک رشته،9 نمیتوان مستقیماً کاراکتری از آن را تغییر داد یا به عبارتی نمیتوان به یک ایندکس از رشته مقداری جدید نسبت داد. با این حال، پایتون مجموعهای از متدهای داخلی رشته فراهم کرده است که با استفاده از آنها میتوان رشتههای جدیدی بر پایهی رشتهی اصلی ساخت. توجه کنید که تمامی این متدها مقدار جدیدی برمیگردانند و رشتهی اصلی را دستکاری نمیکنند.
متد های رشته در پایتون
دقت کنید تمامی متد های زیر فقط و فقط برای رشته ها می باشد و برای اعداد (integer ) نمی باشد.
1-متد lower() در پایتون
این متد تمام حروف بزرگ موجود در رشته را به حروف کوچک تبدیل میکند.
معمولاً زمانی از lower() استفاده میشود که بخواهیم ورودی کاربر را با یک مقدار مشخص مقایسه کنیم، بدون اینکه تفاوت بین حروف بزرگ و کوچک باعث خطا شود.
متد lower فقط روی حروف اثر میگذارد , اعداد و علامتها تغییر نمیکنند.این متد برای مقایسهی متن بسیار مهم است.
text = "Python Is Easy"
result = text.lower()
print(result)
خروجی :
python is easy
1-2متد islower() در پایتون
متد islower() بررسی میکند که آیا تمام حروف موجود در رشته کوچک هستند یا نه. اگر تمام حروف کوچک باشند و حداقل یک حرف در رشته وجود داشته باشد، مقدار True برمیگرداند؛ در غیر این صورت False.اگر حتی یک حرف بزرگ در رشته وجود داشته باشد، نتیجه False خواهد بود.
text = "python"
print(text.islower()) #True
2-متد upper() در پایتون
برای تبدیل تمام حروف رشته به حروف بزرگ می باشد.
text = "python is easy"
result = text.upper()
print(result)
خروجی :
PYTHON IS EASY
2-1متد isupper() در پایتون
متد isupper() بررسی میکند که آیا تمام حروف موجود در رشته بزرگ هستند یا نه. مانند islower()، باید حداقل یک حرف در رشته وجود داشته باشد.اگر رشته شامل حرف کوچک باشد، مقدار False برمیگرداند.
text = "PYTHON"
print(text.isupper()) #True
اعداد، فاصلهها و علامتها توسط این متدها نادیده گرفته میشوند، اما اگر رشته هیچ حرفی نداشته باشد، نتیجه همیشه False است.
print("123".islower()) # False
print("123".isupper()) # False
print("!!!".islower()) # False
3-متد capitalize()درپایتون
این متد فقط اولین کاراکتر رشته را بزرگ میکند و بقیه را کوچک میکند.
text = "pYTHON IS FUN"
result = text.capitalize()
print(result)
خروجی :
Python is fun
4-متد title()در پایتون
این متد برای بزرگ کردن اولین حرف هر کلمه می باشد.
text = "welcome to python world"
result = text.title()
print(result)
خروجی
Welcome To Python World
5-متد strip() در پایتون
برای حذف فاصلههای اضافی از ابتدا و انتهای رشته به کار می رود.این فاصلهها معمولاً هنگام دریافت ورودی کاربر ایجاد میشوند.
text = " hello world "
result = text.strip()
print(result)
خروجی
hello world
6-متد lstrip() در پایتون
فاصله ها را از سمت چپ رشته حذف می کند.
text = " hello"
print(text.lstrip())
7-متد rstrip() در پایتون
فاصله ها را از سمت راست رشته حذف می کند.
text = "hello "
print(text.rstrip())
8-متد replace()در پایتون
متد replace() یکی از مهمترین متدهای رشته در پایتون است که بخشی از متن را با متن جدید جایگزین می کند یعنی اگر کلمه coffee چندین بار در رشته ی ما تکرار شده باشد تمام کلمات coffee برداشته می شود و به جای همه ی آن ها کلمه ی دوم مثل tea جایگزین می شود. .برای تمیز کردن یا اصلاح متن استفاده میشود.
text = "I like coffee"
result = text.replace("coffee", "tea")
print(result)
خروجی:
text = "I like coffee"
result = text.replace("coffee", "tea")
print(result)
اگر نخواهیم متد replace همه ی کلمات را تغییر دهد و فقط تعداد خاصی را تغییر دهد باید در پرانتز سه مقدار بگذاریم و مقدار اخر، عددی باشد که درواقع تعداد تغییراتمون هست .
text = "one one one"
print(text.replace("one", "two", 2))
خروجی:
two two one
اگر بخواهیم در رشته های پایتون چیزی را حذف کنیم ،می توان از متد replace استفاده کرد. در پرانتر پارامتر اول مقداری که قرار هست حذف شود(حتما در کوتیشن ) و پارامتر دوم هم کوتیشنی که درونش هیچ چیزی نباشد(“”) حتی فاصله هم نباشد.
text = "hello!!!"
print(text.replace("!", ""))
در مثال بالا تمامی علامت های تعجب پاک می شود و هیچ چیزی جای آن ها را نمی گیرد.
9-متد split()در پایتون
متد split() یکی از پرکاربردترین متدهای رشته در پایتون است.خروجی این متد همیشه یک لیست است و هر بخش جداشده بهصورت یک رشته در این لیست قرار میگیرد.
این متد به این صورت است که ابتدا جداکننده (separator) مشخص میشود. جداکننده تعیین میکند متن دقیقاً بر اساس چه چیزی تقسیم شود. اگر جداکننده را مشخص نکنیم، پایتون بهصورت پیشفرض متن را بر اساس فاصلهها تقسیم میکند و حتی اگر چند فاصله پشت سر هم وجود داشته باشد، آنها را یک فاصله در نظر میگیرد. برای مثال اگر متنی مثل "apple banana orange" داشته باشیم و روی آن split() را بدون آرگومان اجرا کنیم، خروجی لیستی شامل ['apple', 'banana', 'orange'] خواهد بود. این رفتار باعث میشود split() برای پردازش ورودی کاربر بسیار مناسب باشد، چون فاصلههای اضافی معمولاً مشکلساز نمیشوند.
نکتهی بسیار مهم این است که بین split() و split(" ") تفاوت وجود دارد. وقتی از split(" ") استفاده میکنیم، پایتون دقیقاً به دنبال یک فاصله میگردد و اگر چند فاصله پشت سر هم وجود داشته باشد، آنها را بهعنوان جداکنندههای جداگانه در نظر میگیرد. به همین دلیل در متنی مثل "apple banana"، استفاده از split(" ") منجر به خروجی ['apple', '', '', 'banana'] میشود، در حالی که split() بدون آرگومان فاصلههای اضافی را نادیده میگیرد و خروجی تمیزتری تولید میکند. این تفاوت یکی از دامهای رایج برای افراد تازهکار است.
در نهایت باید توجه داشت که split() نیز مانند تمام متدهای رشته در پایتون، خود رشتهی اصلی را تغییر نمیدهد و همیشه یک خروجی جدید برمیگرداند. این ویژگی باعث میشود بتوان بدون نگرانی از تغییر دادهی اصلی، نسخههای مختلفی از متن را پردازش کرد. اگر این متد را درست بفهمید، بخش بزرگی از کار با متن در پایتون برایتان حل خواهد شد.
1-جدا کردن بر اساس فاصله (پیش فرض متد split)
text = "apple banana orange"
print(text.split())
['apple', 'banana', 'orange']
2-جدا کردن بر اساس فاصله که فرقی با بالایی ندارد.هردو خروجی یکسانی دارد
text = "apple banana orange"
result = text.split(" ")
print(result)
['apple', 'banana', 'orange']
3-جدا کردن بر اساس فاصله .البته در خود رشته چندین فاصله پشت سرهم وجود دارد.
text = "apple banana"
print(text.split(" "))
['apple', '', '', 'banana']
3-جدا کردن بر اساس کاما
text = "red,green,blue"
print(text.split(","))
['red', 'green', 'blue']
4-جدا کردن بر اساس خط فاصله(-)
date = "2026-02-06"
print(date.split("-"))
['2026', '02', '06']
10-متد find() در پایتون
متد find() برای پیدا کردن محل شروع یک زیررشته(شامل یک یا چند تا رشته) داخل یک رشته استفاده میشود. اگر زیررشته در متن وجود داشته باشد، عددی برمیگرداند که نشاندهندهی اندیس شروع آن است و اگر وجود نداشته باشد، مقدار -1 برمیگرداند. مهمترین ویژگی find() این است که هیچوقت خطا ایجاد نمیکند و به همین دلیل برای بررسی وجود یا عدم وجود یک متن، انتخاب امنی محسوب میشود.
برای مثال، اگر رشتهی "python programming" داشته باشیم و text.find("program") را اجرا کنیم، خروجی 7 خواهد بود. اما اگر به دنبال "java" بگردیم، خروجی -1 میشود. این رفتار باعث میشود بتوانیم بهراحتی با شرطها بررسی کنیم که یک کلمه در متن هست یا نه، بدون اینکه برنامه متوقف شود.
text = "python programming"
position = text.find("program")
print(position)
7
text = "python programming"
position = text.find("java")
print(position)
-1
برای اینکه بررسی کنیم یک کلمه بدون ایجاد خطا وجود دارد یا نه:
text = "Welcome to Python"
if text.find("Python") != -1:
print("Word found")
else:
print("Word not found")
11-متد index() در پایتون
متد index() از نظر عملکرد شبیه find() است و اگر زیررشته در متن وجود داشته باشد، همان اندیس شروع را برمیگرداند. تفاوت اصلی این متد با find() در زمانی است که زیررشته پیدا نشود. در این حالت، index() بهجای برگرداندن -1، خطا (ValueError) ایجاد میکند و برنامه متوقف میشود.
برای مثال، text.index("program") خروجی 7 میدهد، اما text.index("java") باعث خطا میشود. به همین دلیل، index() معمولاً زمانی استفاده میشود که مطمئن هستیم زیررشته حتماً در متن وجود دارد یا عمداً میخواهیم در صورت نبودن آن، خطا رخ دهد.
text = "python programming"
position = text.index("program")
print(position) #7
text = "python programming"
position = text.index("java")
print(position)
ValueError: substring not found
مقایسه ی سریع دو متد index و متد find درپایتون
text = "hello world"
print(text.find("world")) # 6
print(text.find("python")) # -1
print(text.index("world")) # 6
# print(text.index("python")) # خطا
12-متد isalpha() در پایتون
متد isalpha() بررسی میکند که آیا رشته فقط شامل حروف انگلیسی است یا نه. اگر تمام کاراکترها حرف باشند و رشته خالی نباشد، مقدار True برمیگرداند؛ در غیر این صورت False.
text = "python"
print(text.isalpha()) #True
اگر رشته شامل فاصله، عدد یا علامت باشد، نتیجه False میشود.
print("python3".isalpha()) # False
print("hello world".isalpha()) # False
13-متد isdigit() در پایتون
متد isdigit() بررسی میکند که آیا رشته فقط شامل عدد است یا نه. این متد فقط ارقام را قبول میکند و علامت منفی یا نقطه اعشاری را عدد در نظر نمیگیرد.
text = "12345"
print(text.isdigit()) #True
print("-123".isdigit()) # False
print("12.5".isdigit()) # False
14-متد isalnum() در پایتون
متد isalnum() بررسی میکند که آیا رشته ترکیبی از حروف و عدد است و هیچ فاصله یا علامت خاصی ندارد. اگر رشته فقط شامل حروف و عدد باشد و خالی نباشد، مقدار True برمیگرداند.
text = "user123"
print(text.isalnum()) #True
15-متد isspace() در پایتون
متد isspace() بررسی میکند که آیا رشته فقط شامل فاصله (space، tab، newline و …) است یا نه. اگر رشته فقط فاصله باشد و خالی نباشد، مقدار True برمیگرداند.اگر حتی یک کاراکتر غیر از فاصله وجود داشته باشد، نتیجه False میشود.
text = " "
print(text.isspace())#True
print(" a ".isspace()) # False
print("".isspace()) # False
16-متد startswith() در پایتون
متد startswith() بررسی میکند که آیا رشته با مقدار مشخصی شروع میشود یا نه. اگر شروع رشته با مقدار دادهشده یکی باشد، True و در غیر این صورت False برمیگرداند.این متد حساس به حروف بزرگ و کوچک است.کاربرد واقعی آن در بررسی نام فایلها، آدرسها (URL) یا فیلتر کردن دادهها بسیار رایج است.
text = "python programming"
print(text.startswith("python")) #True
17-متد endswith() در پایتون
متد endswith دقیقاً برعکس startswith() عمل میکند و بررسی میکند که آیا رشته با مقدار مشخصی تمام میشود یا نه.اگر پایان رشته مطابق مقدار دادهشده نباشد، نتیجه False خواهد بود.این متد معمولاً برای بررسی پسوند فایلها، نوع داده یا اعتبارسنجی ورودی استفاده میشود.
filename = "script.py"
print(filename.endswith(".py"))#True
18-متد count()در پایتون
برای شمارش تعداد تکرار یک کاراکتر یا یک زیررشته در یک رشته استفاده میشود. این متد متن را از ابتدا تا انتها بررسی میکند و هر بار که مقدار مورد نظر را پیدا کند، آن را میشمارد و در نهایت تعداد کل را برمیگرداند. خروجی این متد همیشه یک عدد صحیح است.
برای مثال اگر رشتهی "banana" را داشته باشیم و بخواهیم بدانیم حرف "a" چند بار در آن تکرار شده است، با نوشتن text.count("a") عدد 3 برگردانده میشود. همین متد میتواند برای شمردن یک کلمه کامل هم استفاده شود. مثلاً در رشتهی "one one one two"، اجرای count("one") مقدار 3 را برمیگرداند، چون کلمهی one سه بار بهطور کامل در متن ظاهر شده است.
نکتهی مهم دربارهی count() این است که حساس به حروف بزرگ و کوچک است. یعنی "Python" و "python" برای این متد دو مقدار متفاوت هستند. اگر بخواهیم این حساسیت را از بین ببریم، معمولاً قبل از استفاده از count()، متن را با lower() یا upper() یکسانسازی میکنیم. همچنین باید توجه داشت که count() فقط تکرارهای غیرهمپوشان را میشمارد؛ یعنی اگر الگوها روی هم بیفتند، آنها را جداگانه حساب نمیکند.
text = "Python python PYTHON"
print(text.count("python")) #3
متد count() در پایتون پارامترهای اختیاری start و end هم دارد که به ما اجازه میدهند فقط بخشی از رشته را بررسی کنیم. این ویژگی زمانی مفید است که بخواهیم شمارش را به یک بازهی خاص محدود کنیم؛ مثلاً فقط نیمهی اول متن یا بخشی بعد از یک نقطهی مشخص.در متد count()، عدد اول اندیس شروع و عدد دوم اندیس پایان را مشخص میکند؛ یعنی پایتون فقط همان بازه از رشته را بررسی میکند. توجه داشته باش که اندیس پایان شامل نمیشود و شمارش همیشه از صفر شروع میشود.
text = "banana"
print(text.count("a", 1, 4))#2
b a n a n a
0 1 2 3 4 5
a n a
1 2 3
علاوه بر متد های بالا ،تابع len هم یک تابع داخلی (built-in function) پایتون است که برای محاسبهی طول دادهها استفاده میشود.
در مورد رشته (String)، len() تعداد کل کاراکترها را برمیگرداند؛ شامل حروف، اعداد، فاصلهها و علامتها.
text = "hello world"
print(len(text)) #11
اتصال رشتهها (String Concatenation)
اتصال رشتهها یا چسباندن رشتهها به هم یکی از عملیات پایهای روی متن است. برای اتصال دو رشته به یکدیگر کافیست از عملگر + استفاده کنید. به عنوان مثال:
a = "Hello"
b = "World"
c = a + b
print(c) # خروجی: HelloWorld
در مثال بالا، رشتههای a و b مستقیماً به هم متصل شدهاند. برای افزودن فاصله یا هر کاراکتر دیگر بین دو رشته، میتوان آن کاراکتر را به صورت یک رشتهی جداگانه در میان آنها قرار داد:
c = a + " " + b
print(c) # خروجی: Hello World
در اینجا یک فضای خالی (” “) بین دو رشته قرار دادهایم تا در نتیجهی نهایی فاصله رعایت شود. علاوه بر عملگر +، در پایتون میتوان از عملگر * نیز برای تکرار یک رشته استفاده کرد؛ مثلاً “Hi” * 3 نتیجه “HiHiHi” خواهد داشت. همچنین برای اتصال تعداد زیادی رشته (مثلاً اتصال المانهای یک لیست)، استفاده از متد join به جای + پیشنهاد میشود که در بخش متدهای رشته به آن اشاره خواهیم کرد.
F String در پایتون (فرمت دهی به رشته ها)
در برنامهنویسی، اغلب نیاز است مقادیر متغیرها را درون یک رشته قرار دهیم یا قالببندی خاصی را روی اعداد و متن اعمال کنیم. پایتون برای این کار چند روش دارد که جدیدترین و رایجترین آن استفاده از f strings در پایتون است. از نسخهی 3.6 به بعد، با قرار دادن حرف f قبل از آغاز کوتیشن رشته، میتوان مستقیماً expressionها (مثل متغیر یا حاصل یک تابع/عملیات) را داخل آکولاد {} درون متن قرار داد. به عنوان مثال:
name = "Alice"
age = 30
print(f"My name is {name} and I am {age} years old.")
# خروجی: My name is Alice and I am 30 years old.
در رشتهی بالا، مقادیر متغیرهای name و age در مکانهای مشخص شده قرار گرفتهاند. مزیت f string این است که میتوانید مستقیماً هر عبارت پایتونی را داخل آکولاد قرار دهید؛ برای مثال انجام محاسبات یا استفاده از شرطها:
score = 85
print(f"You have {'passed' if score >= 60 else 'failed'} the exam.")
# خروجی: You have passed the exam.
در این مثال، عبارت شرطی داخل آکولاد اجرا شده و نتیجهی آن (“passed” یا “failed”) در رشتهی نهایی قرار میگیرد. روش قدیمیتر برای قالببندی رشتهها استفاده از متد ()format است. در این روش به جای قرار دادن مستقیم متغیرها در متن، از {} در رشته استفاده میشود و سپس مقادیر به متد format پاس داده میشوند تا به ترتیب در محل {}ها قرار گیرند. برای مثال:
template = "My name is {} and I am {} years old."
print(template.format(name, age))
# خروجی: My name is Alice and I am 30 years old.
در صورت نیاز میتوانید داخل {} مشخص کنید که هر مقدار در کدام موقعیت قرار گیرد (با استفاده از اندیس عددی داخل آکولاد) یا حتی از نامهای کلیدی استفاده کنید، اما در اغلب موارد رعایت ترتیب قرارگیری کافی است. با اینکه متد format نسبت به رشتههای f انعطافپذیری کمتری دارد، دانستن آن برای حفظ سازگاری با نسخههای قدیمیتر پایتون یا کدهای legacy مفید است. همچنین عملگر درصد (%) نیز در پایتون برای قالببندی رشته (مشابه زبان C) وجود دارد که امروزه کمتر استفاده میشود.
کاراکترهای ویژه در رشتهها (Escape Characters)
گاهی لازم است در رشته از کاراکترهایی استفاده کنیم که به طور عادی ممکن است باعث بروز خطا شوند یا مفهوم خاصی داشته باشند. برای مثال، در نظر بگیرید میخواهیم در یک رشته ، علامت کوتیشن دوتایی قرار دهیم. در چنین حالتی پایتون انتهای رشته را اشتباهاً زودتر تشخیص میدهد و کد دچار خطا میشود. به این کاراکترهای خاص یا غیرمجاز در متن، کاراکتر ویژه میگوییم. راهحل پایتون برای درج این کاراکترهای ویژه، استفاده از کاراکتر گریز (escape character) است. کاراکتر گریز یک بکاسلش \ است که قبل از کاراکتر خاص موردنظر قرار میگیرد و به پایتون اعلام میکند که کاراکتر بعدی را به شکل ویژهای تفسیر کند. برای مثال، عبارت زیر بدون استفاده از بکاسلش نامعتبر است:
print("We are the "Vikings" from the north.") – این دستور خطا میدهد
اما با قرار دادن یک بکاسلش قبل از نقلقولهای داخلی، پایتون متوجه میشود که منظور ما درج خود علامت " در متن است نه پایان رشته:
print("We are the \"Vikings\" from the north.")
# خروجی: We are the "Vikings" from the north.
در رشتهی بالا، از “\ برای نمایش خود کوتیشن داخل متن استفاده کردهایم. به طور مشابه برای نمایش خود بکاسلش، آن را دوبار مینویسیم (\\)، یا برای ایجاد خط جدید از n\ استفاده میکنیم. برخی از کاراکترهای ویژهی پرکاربرد در پایتون عبارتاند از: ‘\ (نمایش خود علامت نقلقول تکی)، “\ (نمایش علامت نقلقول دوتایی)، \\ (نمایش بکاسلش)، n\ (پرش به خط بعدی)، t\ (تب یا فاصلهی افقی)، b\ (بکاسپیس) و … . اگر به هر دلیل بخواهید جلوی تفسیر خاص کاراکترهای ویژه را بگیرید (مثلاً در مسیرهای ویندوز یا عبارتهای منظم – regex – که در آنها بکاسلش زیاد استفاده میشود)، میتوانید از رشته خام (raw string) استفاده کنید
رشتهی خام با پیشوند r قبل از کوتیشن مشخص میشود و تمام بکاسلشها را دقیقاً به همان شکل در نظر میگیرد. به طور مثال:
path = r"C:\Users\nima\Docs\newfile.txt"
print(path)
# خروجی: C:\Users\nima\Docs\newfile.txt
در رشتهی بالا، بر خلاف حالت عادی، n\ به عنوان خط جدید تفسیر نشده و دقیقاً کاراکترهای \ و n در خروجی ظاهر شدهاند.
text = "Hello World"
print(text.find("World")) # خروجی: 6
print(text.find("Python")) # خروجی: -1 (زیر رشته یافت نشد)
words = ["Python", "is", "fun"]
print(" ".join(words)) # خروجی: Python is fun
این متدها تنها بخشی از امکانات کار با رشتهها در پایتون هستند. تسلط بر رشتهها و متدهای آنها به شما کمک میکند تا عملیات متنی را به شکل مؤثرتری انجام دهید. توصیه میشود برای تمرین بیشتر، هر یک از مثالهای بالا را اجرا کرده و خروجی آن را مشاهده کنید تا درک عمیقتری از رفتار رشتهها در پایتون به دست آورید.
پیمایش در استرینگ ها
یکی دیگر از ویژگی های رشته ها در پایتون،قابل پیمایش بودن رشته ها است.
قابل پیمایش بودن(Iteration) یکی از ویژگیهای مهم استرینگها در پایتون است. از آنجایی که استرینگ یک نوع دادهی ترتیبی (sequence) محسوب میشود، میتوان روی حروف آن به ترتیب، از ابتدا تا انتها، پیمایش انجام داد. این یعنی پایتون امکان میدهد هر کاراکتر یک متن را جداگانه بررسی کنیم، بدون اینکه لازم باشد متن را به بخشهای کوچکتر تقسیم کنیم یا ساختار دیگری بسازیم.این ویژگی باعث میشود پردازش متن بسیار ساده و خوانا انجام شود. با استفاده از پیمایش(iteration) میتوان کارهایی مثل شمارش حروف، بررسی وجود یک کاراکتر خاص، فیلتر کردن برخی حروف یا ساختن یک رشتهی جدید را بهراحتی انجام داد.
کاربرد مهم دیگر آن در تحلیل و پاکسازی متن است. برای مثال در برنامههایی که با دادههای متنی کار میکنند، از iteration برای حذف فاصلههای اضافی، نادیده گرفتن برخی کاراکترها، یا ساختن یک متن استاندارد استفاده میشود. همچنین در جستجو و بررسی الگوها (مثل پیدا کردن یک حرف یا کلمه خاص)، اعتبارسنجی دادهها (مثلاً بررسی اینکه یک رمز عبور شامل عدد یا حرف خاص هست یا نه) و حتی در پردازش فایلهای متنی، iteration روی استرینگ نقش اساسی دارد. به طور کلی، هر جا نیاز باشد متن بهصورت دقیق و مرحلهبهمرحله بررسی شود، از iteration استرینگها استفاده میشود.
برای پیمایش یک استرینگ یا بررسی تک تک کاراکتر ها از حلقه for در پایتون برای رشته ها استفاده می شود که در مقاله ی مربوط به حلقه ها در پایتون به صورت کامل توضیح داده شده است.
منابع استفاده شده:
w3schools






